Guía Completa de Monitoreo Open Source para Startups
DevOps
Guía práctica para startups sobre cómo desplegar Prometheus, Grafana y Loki, configurar SLOs, alta disponibilidad y optimizar retención y costes.

El monitoreo es clave para startups que buscan evitar problemas técnicos y mantener un servicio estable. Usar herramientas de código abierto como Prometheus, Grafana y Loki permite supervisar métricas, logs y trazas sin incurrir en costes de licencia. Estas herramientas destacan por ser económicas, ligeras en recursos y ofrecer control total sobre los datos.
Resumen rápido:
Prometheus: Recopila métricas numéricas y permite alertas automáticas.
Grafana: Visualiza datos en dashboards interactivos.
Loki: Administra logs con bajo consumo de recursos.
Beneficios: Sin costes de licencia, control de datos, y fácil integración con tecnologías como Docker y Kubernetes.
El artículo explica cómo implementar estas herramientas, desde configuraciones básicas hasta sistemas avanzados con alta disponibilidad usando Thanos, y cómo integrarlas con entornos contenedorizados. También detalla cómo establecer objetivos de nivel de servicio (SLOs) y políticas de retención para optimizar costes.
¿El resultado? Un sistema de monitoreo eficiente, económico y escalable, ideal para startups con recursos limitados.
Building an Open Source Observability Stack from Raw Telemetry
Principales herramientas de monitoreo open source para startups
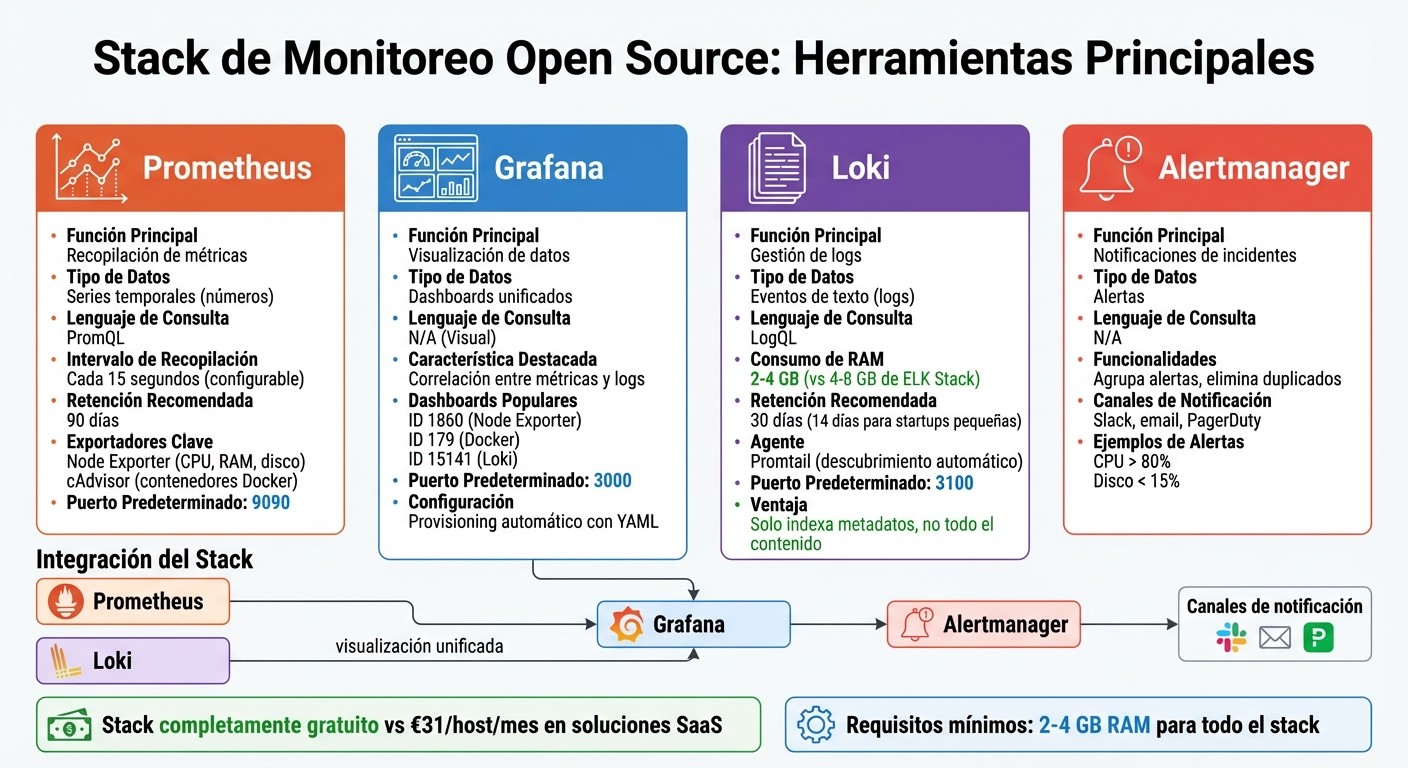
Comparación de herramientas open source de monitoreo: Prometheus, Grafana, Loki y Alertmanager
Para una startup, contar con herramientas de monitoreo es clave para garantizar la estabilidad y el rendimiento de sus sistemas. Afortunadamente, existen soluciones open source que ofrecen las funcionalidades necesarias sin generar costes adicionales. Un stack popular y efectivo incluye Prometheus, Grafana y Loki, que juntos permiten recopilar métricas, gestionar logs y visualizarlos de forma centralizada.
Prometheus para la recopilación de métricas
Prometheus utiliza un modelo de extracción ("pull") para recopilar métricas numéricas de los sistemas a intervalos regulares, normalmente cada 15 segundos. Estos datos se almacenan en una base de datos de series temporales (TSDB) y pueden ser analizados mediante PromQL, su lenguaje de consulta.
Para facilitar la integración, Prometheus utiliza exportadores que convierten datos en un formato legible. Por ejemplo, Node Exporter recopila métricas de hardware como CPU, RAM y disco, mientras que cAdvisor ofrece visibilidad sobre contenedores Docker. Con estos exportadores, una startup puede empezar a monitorear recursos en pocos minutos.
Además, Prometheus se complementa con Alertmanager, una herramienta que gestiona notificaciones automáticas cuando las métricas superan ciertos umbrales. Alertmanager agrupa alertas similares, elimina duplicados y las envía a canales como Slack, correo electrónico o PagerDuty. Por ejemplo, puede alertar si el uso de CPU supera el 80% o si el espacio en disco cae por debajo del 15%. Este sistema, junto con Grafana, facilita una supervisión más completa.
Grafana para la visualización de datos
Grafana funciona como la interfaz principal para visualizar métricas y logs en dashboards interactivos. Conecta múltiples fuentes de datos como Prometheus y Loki, ofreciendo una vista unificada y personalizable. En lugar de crear dashboards desde cero, las startups pueden aprovechar los que ya están disponibles en la comunidad. Por ejemplo, el ID 1860 incluye métricas de Node Exporter, el ID 179 muestra datos de contenedores Docker y el ID 15141 está diseñado para logs de Loki.
Una de las mayores ventajas de Grafana es su capacidad para correlacionar métricas y logs. Si un gráfico de CPU en Prometheus muestra un pico, puedes hacer clic en ese punto y ver los logs relacionados en Loki, lo que reduce el tiempo necesario para investigar problemas.
Además, Grafana permite automatizar configuraciones mediante archivos YAML. Esto facilita la preconfiguración de fuentes de datos y dashboards al iniciar el contenedor, eliminando la necesidad de configuraciones manuales.
Loki para la gestión de logs
Loki es una solución eficiente de gestión de logs inspirada en Prometheus. En lugar de indexar todo el contenido de los logs, Loki solo indexa metadatos como etiquetas, lo que lo hace mucho más ligero en términos de almacenamiento. Por ejemplo, Loki puede operar con tan solo 2–4 GB de RAM, mientras que alternativas como ELK Stack necesitan al menos 4–8 GB solo para arrancar.
Para enviar logs a Loki, se utiliza Promtail, un agente que detecta archivos de log, les asigna etiquetas y los envía al servidor Loki. Estas etiquetas, como env="prod" o service="api", permiten correlacionar datos entre Prometheus y Loki en los dashboards de Grafana.
Herramienta | Función principal | Tipo de datos | Lenguaje de consulta |
|---|---|---|---|
Prometheus | Recopilación de métricas | Series temporales (números) | PromQL |
Loki | Agregación de logs | Eventos de texto (logs) | LogQL |
Grafana | Visualización | Dashboards unificados | N/A (Visual) |
Alertmanager | Notificaciones de incidentes | Alertas | N/A |
En general, las startups suelen configurar 90 días de retención de métricas en Prometheus y 30 días de retención de logs en Loki. Esto ayuda a controlar el crecimiento del almacenamiento y mantiene la infraestructura bajo control en términos de costes.
Opciones de configuración avanzada e integración
Con el stack básico funcionando, es hora de llevar el monitoreo al siguiente nivel. Muchas startups optimizan su infraestructura con configuraciones avanzadas que permiten escalar sistemas, asegurar alta disponibilidad y alinear el rendimiento técnico con los objetivos empresariales.
Alta disponibilidad con Thanos

Thanos amplía las capacidades de Prometheus al ofrecer almacenamiento a largo plazo y alta disponibilidad sin necesidad de duplicar datos manualmente. En lugar de operar dos instancias de Prometheus con datos fragmentados, Thanos utiliza un componente llamado Querier, que agrega y deduplica métricas de múltiples réplicas automáticamente.
La arquitectura de Thanos se basa en sidecars que operan junto a cada instancia de Prometheus. Estos sidecars suben bloques de datos cada dos horas a servicios de almacenamiento de objetos como AWS S3, Google Cloud Storage o Azure Blob Storage. Además, el Store Gateway permite al Querier acceder a datos históricos almacenados en la nube, mientras que el Compactor optimiza el almacenamiento generando resoluciones de 5 minutos después de 40 horas y de 1 hora tras 10 días.
En un caso documentado por OneUptime en febrero de 2026, se implementó Prometheus v2.45.0 y Thanos v0.32.0 en producción. La configuración incluyó un StatefulSet de Kubernetes con dos réplicas y sidecars de Thanos. Los datos se subían a un bucket de AWS S3 llamado "thanos-metrics" en bloques de dos horas. Un Querier de Thanos se desplegó con la bandera --query.replica-label=replica, proporcionando una interfaz unificada para Grafana, conectada a través de http://thanos-querier.monitoring.svc.cluster.local:10902.
Para que la deduplicación funcione correctamente, cada instancia de Prometheus debe tener etiquetas externas únicas, como replica: A y replica: B, pero etiquetas de cluster idénticas. Con Kubernetes, un Headless Service (ClusterIP: None) permite al Querier descubrir automáticamente todas las réplicas de sidecars mediante registros DNS SRV. Además, es imprescindible ejecutar Prometheus con la bandera --web.enable-lifecycle para que el sidecar pueda recargar configuraciones.
Componente | Función en alta disponibilidad | Requisito de despliegue |
|---|---|---|
Sidecar | Envía datos de Prometheus a la nube | 1 por cada instancia de Prometheus |
Querier | Agrega y deduplica datos | Sin estado, escalable horizontalmente |
Store Gateway | Accede a datos históricos | Escalable según la carga de consultas |
Compactor | Reduce tamaño de datos históricos | Debe ser único (singleton) |
Un punto crítico: nunca ejecutes más de una instancia del Compactor en el mismo bucket, ya que esto podría corromper los datos. Para startups con recursos limitados, configurar una retención local de 2 a 6 horas en Prometheus puede ahorrar espacio en disco, ya que Thanos se encarga del almacenamiento a largo plazo.
El siguiente paso es integrar estas capacidades en entornos contenedorizados.
Integración con Kubernetes y Docker
Integrar el monitoreo con entornos de contenedores requiere visibilidad tanto a nivel de host como de contenedor. Herramientas como cAdvisor recopilan métricas específicas de contenedores Docker (CPU, RAM, I/O), mientras que Node Exporter captura datos del hardware y el sistema operativo del host. Este enfoque asegura un monitoreo eficiente.
En Kubernetes, los Helm charts como prometheus-community y grafana/loki-stack permiten configuraciones consistentes y fáciles de replicar. Para entornos Docker, Promtail puede descubrir contenedores automáticamente a través del socket de Docker (/var/run/docker.sock) y leer logs desde /var/lib/docker/containers.
Grafana simplifica la configuración mediante su función de provisioning, que permite cargar fuentes de datos y dashboards automáticamente con archivos YAML, evitando configuraciones manuales. Además, los "campos derivados" en Grafana facilitan la navegación entre logs en Loki y métricas en Prometheus, agilizando la resolución de problemas.
Para startups con recursos limitados, aumentar el scrape_interval de Prometheus de 15 a 30 o 60 segundos puede reducir considerablemente el consumo de CPU y RAM. Es fundamental proteger las herramientas de monitoreo detrás de un proxy inverso, como Nginx o Traefik, con cifrado SSL/TLS. Nunca expongas directamente los endpoints de Prometheus o Loki a internet.
Con la infraestructura técnica lista, definir SLOs ayuda a alinear las métricas con los objetivos del negocio.
Configuración de Service Level Objectives (SLOs)
Los SLOs establecen metas medibles de rendimiento, como tiempo de actividad, latencia y tasas de error, asegurando que el sistema cumpla con las expectativas del negocio. Grafana facilita la visualización de métricas predefinidas y el seguimiento de SLOs.
Las herramientas modernas de observabilidad permiten monitorear las "tasas de consumo de SLO" (burn rates), que identifican picos de errores o problemas de latencia antes de que se conviertan en violaciones de SLA. Para alertas efectivas, Prometheus Alertmanager puede integrarse con canales como Slack o PagerDuty para notificar cuando se superen umbrales críticos.
Para un seguimiento a largo plazo, soluciones como Thanos o VictoriaMetrics ofrecen la retención histórica necesaria para analizar tendencias. Las startups de unos 50 empleados pueden ahorrar entre 70.000 € y 330.000 € al año al cambiar de soluciones SaaS comerciales a alternativas open source autoalojadas.
En startups pequeñas, una retención de 14 días en Loki suele ser suficiente, mientras que 30 a 90 días en Prometheus permite un análisis efectivo de tendencias de SLO.
Ejemplos de implementación para startups
Con la arquitectura avanzada definida, el siguiente paso es llevar estas soluciones a un entorno real. Aquí se presentan dos enfoques que las startups pueden adoptar según sus necesidades y recursos. Estas implementaciones prácticas son una forma de materializar los conceptos avanzados previamente discutidos.
Stack Prometheus + Grafana + Loki
El stack PLG (Prometheus, Loki, Grafana) permite un control completo de los datos sin incurrir en costes de licencia. Por ejemplo, mientras que herramientas como Datadog pueden costar unos 31 € por host al mes, este stack es completamente gratuito y autoalojado.
La forma más rápida de implementarlo es mediante Docker Compose, lo que permite desplegar todos los componentes en cuestión de minutos con un único archivo docker-compose.yml. Este stack consta de seis componentes principales:
Componente | Función | Puerto predeterminado |
|---|---|---|
Prometheus | Recopilación de métricas | 9090 |
Grafana | Visualización | 3000 |
Loki | Agregación de logs | 3100 |
Promtail | Envío de logs | 9080 |
Node Exporter | Métricas del sistema operativo | 9100 |
cAdvisor | Métricas de contenedores | 8080 |
La configuración del entorno se realiza en seis pasos:
Instalar Docker y Docker Compose.
Crear
prometheus.ymlpara definir los trabajos de scraping de Node Exporter y cAdvisor.Configurar
loki-config.ymlcon rutas de almacenamiento y límites de retención.Mapear el socket de Docker (
/var/run/docker.sock) enpromtail-config.yml.Ejecutar
docker-compose up -dpara lanzar todos los contenedores.Acceder a Grafana en el puerto 3000 para añadir fuentes de datos e importar dashboards.
Para simplificar aún más, Grafana permite provisionar fuentes de datos automáticamente mediante un archivo datasources.yml. Además, las startups pueden aprovechar dashboards preconfigurados de la comunidad, como el dashboard 1860 para métricas de Node Exporter, el 179 para Docker y el 15141 para logs de Loki.
"Prometheus + Grafana + Loki es el stack open source que necesitas: autoalojado, gratuito, con métricas profundas, logs centralizados y dashboards profesionales." - ziru, Autor, El Diario IA
Este stack funciona eficientemente con solo 2-4 GB de RAM, en comparación con los 4-8 GB que suele requerir el stack ELK. Para aplicar políticas de retención, configura --storage.tsdb.retention.time=30d en Prometheus y retention_period: 720h en Loki. Si el consumo de recursos es alto, aumentar el scrape_interval a 30 o 60 segundos puede aliviar la carga de CPU y memoria.
Aunque el stack PLG ofrece control y optimización de recursos, quienes prefieran una solución más integrada pueden optar por SigNoz.
SigNoz como solución todo en uno
SigNoz combina métricas, trazas distribuidas y logs en una única interfaz, basada en OpenTelemetry. Con más de 24.000 estrellas en GitHub, cuenta con el respaldo de una amplia comunidad de desarrolladores.
Ofrece dos opciones de despliegue: una versión gestionada en la nube (SigNoz Cloud) y una versión open source autoalojada. Los nuevos usuarios de SigNoz Cloud disponen de 30 días de acceso completo a todas las funcionalidades.
"La forma más fácil de ejecutar SigNoz es usar SigNoz Cloud: sin instalación, mantenimiento ni escalado necesario." - Documentación de SigNoz
Para instrumentar tus aplicaciones, utiliza el SDK de OpenTelemetry, que es compatible con lenguajes como Node.js, Python, Java y Go. Por ejemplo, una empresa de logística utilizó SigNoz para monitorear la latencia de sus APIs y rastrear cambios en el estado de entregas en una arquitectura de microservicios. Esto les permitió identificar cuellos de botella en tiempo real, mejorando la experiencia del cliente.
Startups que gestionen grandes volúmenes de datos (más de 10.000 eventos por segundo) pueden ajustar el tamaño del lote en el otel-collector de 10.000 a 50.000 filas. También es posible reducir el volumen de datos enviados mediante procesadores de muestreo probabilístico, optimizando costes y almacenamiento.
Para configurar alertas efectivas, SigNoz permite vincularlas a objetivos de nivel de servicio (SLOs), asegurando que las notificaciones sean relevantes para la experiencia del usuario. Se recomienda empezar con un dashboard de "Señales Doradas", que incluya métricas como la tasa de solicitudes, la tasa de errores y la latencia P95.
En cuanto al almacenamiento histórico, mover datos antiguos a S3 puede reducir costes, aunque el acceso es 2-3 veces más lento que con EBS. Además, se sugiere ejecutar SigNoz en un clúster separado para aislar el entorno de monitoreo del de las aplicaciones.
Conclusión
Resumen de herramientas y mejores prácticas
Implementar un sistema de monitoreo open source es una decisión estratégica que puede marcar la diferencia en el crecimiento de una empresa. Herramientas como Prometheus, Grafana y Loki destacan como opciones profesionales y gratuitas frente a soluciones SaaS que, en algunos casos, superan los 31 € por host al mes.
Este conjunto de herramientas no solo optimiza recursos, sino que también elimina la dependencia de proveedores externos, ofreciendo un control completo sobre los datos y evitando el riesgo de quedar atado a un único proveedor. Además, su diseño permite abordar los tres pilares de la observabilidad: métricas, para datos numéricos; logs, para entender el contexto de los eventos; y trazas, para seguir el flujo de las solicitudes. Este enfoque integral transforma el monitoreo de reactivo ("el servicio está caído") a proactivo ("el uso de CPU aumentó, aparecieron errores y luego el servicio falló").
Estos principios son el punto de partida para una implementación práctica y efectiva.
Próximos pasos para startups
Con las herramientas y prácticas recomendadas, el siguiente paso es adaptarlas a las necesidades específicas de tu entorno. Puedes empezar con una configuración básica: utiliza Node Exporter para recopilar métricas del sistema y Grafana para visualizarlas. A medida que tu proyecto crezca, amplía y ajusta la configuración según las nuevas necesidades.
Para mantener un equilibrio entre visibilidad y costes, establece políticas de retención adecuadas: por ejemplo, 30 días para métricas y 14 días para logs. Aprovecha los dashboards preconfigurados de la comunidad de Grafana para agilizar la puesta en marcha. Configura alertas que se centren únicamente en notificaciones críticas, evitando saturar a tu equipo con información irrelevante. Y, sobre todo, protege tus dashboards: nunca los expongas directamente a internet; utiliza un proxy inverso, HTTPS y autenticación segura.
Si necesitas apoyo para desplegar un sistema de monitoreo open source que refuerce tanto el rendimiento como la seguridad, puedes contar con el equipo experto de Niom Solutions. Ellos te guiarán en cada paso del proceso.
FAQs
¿Qué debería monitorizar primero en mi startup?
Lo más importante es supervisar la disponibilidad y el rendimiento de tus sistemas e infraestructuras. Es crucial garantizar que tus servidores y servicios estén siempre operativos, y detectar posibles problemas en tiempo real para reducir al máximo los tiempos de inactividad.
Puedes empezar con herramientas básicas como Nagios Core o Zabbix, que son ideales para cubrir necesidades iniciales. A medida que crezca tu startup, considera soluciones más avanzadas como Prometheus y Grafana, que te permitirán analizar métricas más detalladas y específicas.
¿Cuándo me conviene pasar a alta disponibilidad con Thanos?
Es una buena idea elegir alta disponibilidad con Thanos si necesitas asegurar la continuidad del monitoreo a largo plazo. Esto es especialmente útil en entornos con alta carga o donde la criticidad es clave, como ocurre en Kubernetes. Implementar esta solución ayuda a prevenir la pérdida de datos y garantiza que las métricas estén disponibles en todo momento.
¿Cómo proteger Prometheus, Grafana y Loki para que no estén expuestos a Internet?
Para proteger Prometheus, Grafana y Loki, es fundamental implementar proxies inversos. Estos permiten gestionar la autenticación y restringir el acceso a direcciones IP específicas, mejorando así la seguridad. Además, asegúrate de usar TLS para cifrar todas las conexiones, evitando cualquier tipo de acceso no seguro.
En entornos como Kubernetes o similares, refuerza la seguridad configurando redes privadas, firewalls y reglas específicas. Estas medidas limitarán el acceso exclusivamente a redes internas o a direcciones IP previamente autorizadas, reduciendo riesgos potenciales.