Mejores Prácticas CI/CD para SaaS Escalable
DevOps
Prácticas CI/CD para escalar SaaS: trunk-based, IaC, testing 70/20/10, secretos fuera del repo, blue-green/canary y observabilidad.

Si tu SaaS crece, tu pipeline no puede ir “más o menos bien”. Tiene que frenar fallos, permitir despliegues frecuentes y dejar rastro de cada cambio. Ese es el punto central del artículo.
Yo lo resumiría así: para escalar con cabeza, necesito TBD, tests automáticos, IaC, secretos fuera del repo, despliegues blue-green o canary, observabilidad con gates y KPI tipo DORA. No se trata solo de sacar cambios. Se trata de sacar cambios con control, con rollback listo y con cumplimiento metido en el flujo.
Los datos del texto van al grano:
208 veces más despliegues en equipos con pipelines maduros.
7 veces menos fallos en producción.
85 % de vulnerabilidades detectadas antes de producción.
MTTR de horas a minutos con rollback automático.
Objetivo de pipeline: menos de 10 minutos.
En pocas palabras, yo me quedaría con este mapa:
Código: cambios pequeños en rama principal y feature flags.
Calidad: pirámide 70/20/10, contratos entre servicios y smoke tests.
Infra: entornos definidos como código e infraestructura inmutable.
Acceso: OIDC, RBAC y secretos en Vault o gestores cloud.
Despliegue: rolling, blue-green o canary según el riesgo.
Control: métricas, logs, trazas, SLO y rollback si error > 1 %.
Seguimiento: DORA, tiempo de pipeline y tasa de fallo por cambio.
La idea es simple: convertir CI/CD en un sistema que te deje crecer sin perder visibilidad ni control.
Blue-Green vs Canary Deployment: Cuándo Usar Cada Estrategia CI/CD
Accelerating Software Delivery: Building a Scalable CI/CD Pipeline
Por qué CI/CD impulsa el crecimiento en SaaS
Cuando un SaaS empieza a crecer, la operación se complica enseguida: entran más clientes, sube el tráfico y aparecen más servicios que dependen unos de otros. Si los despliegues siguen siendo manuales, el equipo acaba gastando tiempo en tareas repetitivas en vez de dedicarlo a mejorar el producto. CI/CD cambia eso. Convierte la entrega en un proceso predecible y repetible, sin importar el tamaño del sistema.
El efecto en la operación es directo. Un pipeline maduro detecta el 85 % de las vulnerabilidades antes de que lleguen a producción. Y los mecanismos de rollback automático pueden bajar el MTTR de horas a minutos. Dicho de forma simple: menos sobresaltos, menos tiempo apagando fuegos y más margen para sacar cambios con control. Eso sí, ese valor solo aparece cuando el pipeline se prepara para crecer sin meter más riesgo.
El caso de FacturaPro lo deja claro. Pasó de 0,2 despliegues semanales a 3, redujo el MTTR de 6 horas a 25 minutos y bajó los incidentes por despliegue un 60 % tras adoptar un pipeline CI/CD. A partir de ese punto, el reto ya no es solo desplegar más. El foco pasa a estar en controlar ramas, entornos y despliegues sin pisar el freno.
1. Niom Solutions
Bajando de la estrategia a la práctica, Niom Solutions lleva estas medidas a pipelines pensados para crecer sin perder el control. En arquitecturas multi-tenant, la idea es separar bien los recursos compartidos de los recursos propios de cada tenant. Así se evita el clásico problema del vecino ruidoso.
Las actualizaciones no se lanzan de golpe para todo el mundo. Primero se validan sobre un subconjunto de tenants con canary releases y, si todo va bien, luego se amplían al resto. Además, la infraestructura se define como código con herramientas como Terraform o Pulumi, lo que ayuda a tener entornos reproducibles y auditables.
Con el despliegue bajo control, toca comprobar que el cambio no rompe nada. Por eso, el pipeline incluye de serie análisis estático (SAST), análisis dinámico (DAST) y escaneo de dependencias (SCA). También exige que los servicios emitan telemetría OpenTelemetry antes del despliegue.
Las pruebas siguen la pirámide de testing:
70 % unitarias
20 % de integración
10 % E2E en flujos críticos
Este reparto permite validar antes lo más frecuente y dejar las pruebas más pesadas para los recorridos que de verdad importan. En pocas palabras: se gana velocidad sin dejar la puerta abierta a regresiones.
En entornos de alta disponibilidad, Niom Solutions apuesta por infraestructura inmutable, es decir, sin cambios en caliente sobre instancias de producción. A eso suma la gestión de secretos con HashiCorp Vault o AWS Secrets Manager, además del enmascarado de datos sensibles en logs.
2. Trunk-Based Development
Con el despliegue progresivo ya bajo control, el siguiente cuello de botella suele estar en cómo fluye el código. El trunk-based development consiste en integrar cambios pequeños y frecuentes en una sola rama principal varias veces al día. Y esto tiene una ventaja muy clara: si las integraciones son pequeñas, cada cambio pesa menos. Si algo se rompe, se localiza casi al momento, en vez de quedarse perdido entre semanas de trabajo acumulado.
En un SaaS multi-tenant, los feature flags hacen posible desplegar en la rama principal sin enseñar la función a todos los clientes de golpe. El código llega a producción, pero permanece apagado. Luego se activa por tenants poco a poco. Dicho de forma simple: despliegas antes, expones después.
Para que este modelo no se venga abajo, la disciplina con las ramas tiene que ser estricta. Las ramas de funcionalidad deben durar entre 1 y 3 días, y la integración en la rama principal debe bloquearse si fallan el linting, el tipado o los escaneos de seguridad. También conviene mantener el pipeline por debajo de 10 minutos. Si tarda más, la integración continua empieza a atascarse y los cambios dejan de entrar con la cadencia que exige TBD.
3. Pirámide de testing automatizado
Si haces commits diarios en la rama principal, el siguiente paso es claro: evitar regresiones en producción. Y aquí no hay mucho margen. En entornos multi-tenant y con microservicios, un cambio mínimo puede romper servicios compartidos o flujos críticos sin que nadie lo vea venir.
La distribución más común es 70 % unitarios, 20 % de integración y 10 % E2E. Los tests unitarios validan lógica aislada y son los más rápidos. Los de integración comprueban módulos, API y base de datos en conjunto. Los E2E se dejan para los flujos críticos del negocio.
Hay una razón simple detrás de esta pirámide: cuanto más tarde detectas un fallo, más cuesta arreglarlo. Los equipos con pipelines maduros y testing automatizado sufren siete veces menos fallos en los cambios.
En un SaaS multi-tenant, esta forma de repartir las pruebas ayuda a que un ajuste pequeño no termine rompiendo servicios compartidos o recorridos clave. Aquí conviene añadir contract testing orientado al consumidor (CDC) entre microservicios. Y, después de cada despliegue, los smoke tests deberían activar un rollback automático si la tasa de error supera el 1 %.
También merece la pena ejecutar en paralelo los tests unitarios, los de integración y los escaneos de seguridad. Para los E2E, lo normal es tirar de caché y sharding para que no ralenticen todo el pipeline.
La regla es simple: probar pronto, probar en paralelo y dejar los E2E solo para lo que de verdad importa.
4. Infraestructura como Código
Las pruebas detectan fallos. Pero no evitan que el propio entorno los tape. Ahí entra la Infraestructura como Código (IaC): redes, balanceadores y reglas de acceso se definen en archivos versionados, no tocando cosas a mano.
Cuando no usas IaC, desarrollo, staging y producción suelen acabar con pequeñas diferencias. Y ese “pequeñas” es justo el tipo de detalle donde se esconden los bugs imposibles de repetir. Con IaC, cada entorno nace de la misma definición. Eso incluye la separación entre recursos compartidos y recursos propios de cada cliente.
Cuando el tráfico crece, la infraestructura inmutable ayuda a bajar el riesgo de cada cambio y hace más simple el rollback. En vez de parchear instancias en producción, despliegas instancias nuevas y versionadas. Si algo sale mal, vuelves a la versión anterior al momento. Con el estado bajo control, el siguiente paso es dejar claro cómo desplegar sin cortar el servicio.
Terraform suele destacar por su ecosistema y por cómo maneja el estado. Pulumi encaja mejor si el equipo prefiere definir infraestructura con TypeScript, Python o Go.
En Terraform, la gestión del estado no conviene dejarla al azar. Usa siempre un backend remoto - S3 + DynamoDB con bloqueo de estado - para evitar conflictos.
También merece la pena apoyarse en Golden Paths: plantillas de infraestructura ya aprobadas para patrones comunes. En la práctica, esto convierte IaC en autoservicio con control, permite aprovisionar entornos sin fricción y recorta diferencias entre entornos.
5. Gestión de Entornos y Secretos
Cuando la infraestructura ya está estandarizada, el siguiente frente de riesgo suele estar en los secretos y los permisos. La regla aquí es simple: no guardes secretos en el repositorio. Es mejor centralizarlos en gestores dedicados y rotar las credenciales de forma automática para acortar la ventana de exposición.
El siguiente paso es igual de importante: quitar las credenciales permanentes. En lugar de dejar claves fijas dando vueltas, autentica el pipeline en la nube con identidades temporales mediante OIDC o federación de identidades de carga de trabajo. Así reduces el daño si algo se filtra.
Hay otro punto que a veces se pasa por alto. Un secreto expuesto en el historial puede seguir accesible aunque se corrija después. Dicho de otro modo: borrarlo del último commit no siempre arregla el problema. Por eso conviene auditar el historial del repositorio con herramientas como TruffleHog o Gitleaks y conservar los logs de auditoría en almacenamiento WORM, para evitar cambios retroactivos.
Tampoco todos los entornos merecen el mismo nivel de automatización. Separar la configuración por entorno y tenant ayuda a evitar cruces de permisos y errores tontos. Además, conviene clasificar los entornos por criticidad y aplicar el principio de mínimo privilegio: aprobación manual en los más sensibles y RBAC con permisos granulares para limitar el acceso a secretos de producción.
Con este control sobre secretos y permisos, el pipeline puede validar cambios sin exponer datos sensibles.
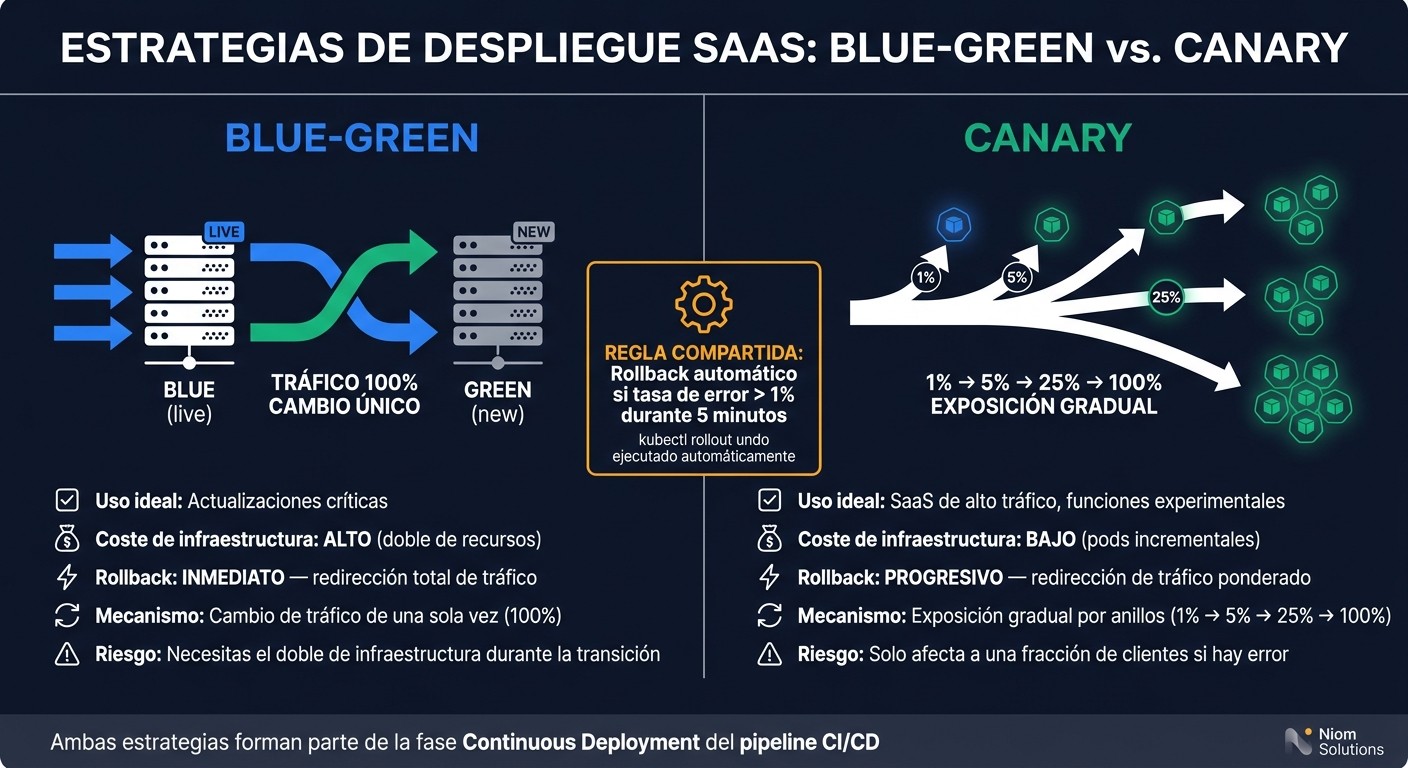
6. Despliegues Blue-Green y Canary
Blue-green y canary sirven para desplegar sin cortar el servicio. Los dos patrones permiten llevar cambios a producción sin dejar a los clientes tirados. La clave está en elegir el que mejor limite el golpe si algo sale mal.
El enfoque blue-green mantiene dos entornos de producción idénticos. El entorno blue atiende el tráfico actual, mientras green recibe la nueva versión. Cuando todo está validado, el tráfico se redirige de una sola vez. Si aparece un problema, el rollback es inmediato: solo hay que volver a enviar el tráfico al entorno anterior. La contrapartida es simple: durante la transición necesitas el doble de infraestructura.
El enfoque canary va paso a paso. La nueva versión se muestra primero a una parte pequeña del tráfico - 1 %, 5 % y 25 % - antes de llegar al despliegue completo. Eso reduce el radio de impacto. Si hay un error, solo afecta a una fracción de los clientes. En un SaaS multi-tenant, conviene limitar el canary a tráfico de bajo riesgo y avanzar por anillos de exposición.
Usa blue-green para cambios críticos y canary cuando quieras validar con tráfico real:
Criterio | Blue-Green | Canary |
|---|---|---|
Uso ideal | Actualizaciones críticas | SaaS de alto tráfico, funciones experimentales |
Coste de infraestructura | Alto (doble de recursos) | Bajo (pods incrementales) |
Rollback | Inmediato | Progresivo, mediante redirección de tráfico ponderado |
Ambas estrategias encajan en la fase de Continuous Deployment del pipeline. Ahí se puede automatizar tanto el cambio de tráfico como el rollback. Una práctica muy usada es configurar el pipeline para ejecutar kubectl rollout undo de forma automática si la tasa de errores supera el 1 % durante 5 minutos. Sin métricas en tiempo real, este tipo de despliegue va un poco a ciegas. Con métricas buenas, en cambio, sabes cuándo seguir y cuándo frenar.
Y el despliegue no acaba en la aplicación. El esquema de datos también tiene que avanzar sin bloquear a nadie. Las migraciones de base de datos deben ser compatibles hacia atrás. Si la nueva versión cambia el esquema, la versión anterior tiene que seguir funcionando con él mientras dura la transición. El patrón expand and contract - añadir primero la nueva columna, migrar los datos y eliminar la antigua después - es la forma más segura de hacerlo. Medir error y latencia en cada anillo de exposición es lo que te da criterio para avanzar o revertir.
7. Observabilidad integrada en el pipeline
Después de definir blue-green y canary, toca medir qué está pasando en tiempo real. Aquí es donde la observabilidad dentro del pipeline marca la diferencia: decide si un despliegue sigue adelante o si hay que frenarlo y volver atrás.
La idea es simple. No conviene esperar a producción para mirar señales. Si instrumentas métricas, logs y trazas desde la compilación y las pruebas, puedes relacionar lo que ocurre en toda la arquitectura y no solo al final del camino. OpenTelemetry es el estándar para hacerlo de forma agnóstica al proveedor.
En un SaaS multi-tenant, este punto se vuelve aún más delicado. Los datos tienen que correlacionarse por tenant ID. Detectar un error 5xx no basta. Hay que saber a qué cliente afecta y si el fallo está aislado o si se está extendiendo al resto. Luego, esas señales pasan a alimentar los KPI del propio pipeline.
Las SLO también deben tener peso real. No pueden quedarse como una referencia bonita en un panel. Tienen que bloquear la promoción cuando toca. Si el canary consume el presupuesto de error, el pipeline detiene la promoción o revierte el cambio.
Señal | Qué capturar | Para qué sirve en SaaS |
|---|---|---|
Métricas | Latencia (p99), errores 5xx, CPU y memoria | Detecta cuellos de botella y agotamiento de recursos |
Logs | JSON estructurado, tenant ID, correlation ID | Depuración rápida en microservicios distribuidos |
Trazas | Flujo de la petición, dependencias entre servicios | Identifica interferencia entre tenants en entornos multi-tenant |
SLOs | Error budget restante, cumplimiento de SLIs | Equilibra la velocidad de entrega con la estabilidad de la plataforma |
Cuando el pipeline exige esta instrumentación antes del despliegue, el equipo deja de llegar a producción a ciegas y reduce el riesgo desde el minuto uno.
8. Mejora continua guiada por KPI
Las métricas de observabilidad del punto anterior te cuentan qué está pasando ahora. Los KPI del pipeline contestan otra cosa: si el equipo está mejorando con el paso del tiempo. Sin esa vista, el equipo apaga fuegos, pero no termina de avanzar. Por eso, después de observar, toca medir si el pipeline mejora de forma estable.
El punto de partida son las métricas DORA: frecuencia de despliegue, lead time (tiempo de entrega de cambios), tasa de fallos en producción (change failure rate) y tiempo medio de recuperación (MTTR). Los equipos más maduros despliegan bajo demanda y mantienen un lead time por debajo de 1 hora. Esa diferencia se nota en el día a día: más capacidad para crecer y menos deuda operativa acumulada.
En entornos SaaS, hay dos KPI que dan control directo sobre lo que pasa en el pipeline:
Tiempo total de ejecución del pipeline: la meta es bajar de 10 minutos, para que los desarrolladores no pierdan el contexto de lo que estaban haciendo.
Porcentaje de vulnerabilidades detectadas en CI: un escáner de CI puede bloquear el 85 % de las vulnerabilidades antes de que lleguen a producción.
En un SaaS multi-tenant, no basta con mirar estos datos en bloque. Hay que leerlos por cliente. En arquitecturas multi-tenant, estos KPI deben segmentarse por tenant para detectar degradaciones aisladas por tenant antes de que escalen. Así ves qué tenant está sufriendo una degradación antes de que arrastre al resto, y eso ayuda a cumplir los SLA con más precisión.
El siguiente paso es convertir esos KPI en puertas automáticas. Por ejemplo, puedes congelar despliegues cuando se agote el error budget y lanzar rollout undo si la tasa de error supera el 1 % durante 5 minutos. Con los KPI ya fijados, el paso siguiente es usarlos como criterio de prueba y promoción.
Estrategia de pruebas para escalar con seguridad
Con los KPI ya fijados como criterio de promoción, el siguiente paso es claro: asegurarte de que el pipeline tiene una base de pruebas capaz de aguantar el crecimiento sin convertirse en un cuello de botella. La idea no es meter más tests porque sí. La prioridad está en detectar fallos antes sin alargar el ciclo.
Funciona bien partir de una pirámide 70/20/10 y ejecutar en paralelo el linting, las pruebas unitarias y los chequeos de seguridad para recortar el tiempo del pipeline. Las unitarias deberían terminar en menos de 2 minutos, las de integración en menos de 10 y las pruebas end-to-end (E2E) en menos de 20. Cuando paralelizas trabajos independientes, el tiempo total del pipeline puede bajar hasta un 33 %. Y cuando esa base está bajo control, toca pasar al siguiente filtro: bloquear defectos y secretos desde el primer cambio.
Aquí conviene integrar SAST, SCA y escaneo de secretos desde el primer commit. Llevar estas comprobaciones a las fases más tempranas del pipeline permite detectar el 85 % de las vulnerabilidades antes de que lleguen a producción. En la práctica, eso convierte la seguridad en un gate automático de promoción, no en una revisión tardía que llega cuando el código ya está a punto de salir.
En SaaS multi-tenant, los tests de contrato ayudan a evitar roturas silenciosas entre servicios. Cuando trabajas con servicios compartidos y despliegues parciales, el Consumer-Driven Contract Testing permite asegurar la compatibilidad entre versiones sin tener que desplegar los servicios juntos. Dicho de forma simple: cada equipo puede avanzar a su ritmo sin jugarse una sorpresa en producción. Y si una prueba tiene una tasa de éxito por debajo del 95 %, debería ir a cuarentena.
Los tipos de prueba que sostienen esta estrategia son:
Unitarias: validan lógica aislada desde el primer commit.
Integración / API: comprueban la comunicación entre módulos y servicios.
Contrato (CDC): garantizan compatibilidad entre interfaces en entornos multi-tenant.
Seguridad (SAST / SCA): bloquean vulnerabilidades y secretos antes de producción.
E2E y rendimiento: cubren flujos críticos y validan el comportamiento bajo carga en staging o canary.
Diseño de entornos y gestión de configuración
Una vez validado el código, el problema cambia: ya no se trata solo de probar, sino de reproducir entornos y mover cambios sin ensuciar producción. Por eso, una arquitectura CI/CD bien pensada separa desarrollo, integración, staging y producción. Esa división ayuda a aislar riesgos y a aplicar el principio de mínimo privilegio. Además, cada promoción debe pasar por gates automáticos y smoke tests en staging antes de llegar a producción.
El siguiente punto crítico no es el test, sino el acceso. Dicho de forma simple: quién despliega y con qué credenciales. Las credenciales no deberían vivir dentro del pipeline ni ser permanentes. OIDC permite cambiar la identidad del pipeline por credenciales temporales. Y cuando hace falta un control más estricto, herramientas como HashiCorp Vault, AWS Secrets Manager o Azure Key Vault sirven para centralizar el acceso a secretos.
Ese aislamiento no debería quedarse en una intención escrita en un documento. Conviene dejarlo fijado en una definición versionada para que todos los entornos nazcan de la misma forma. Define cada entorno como código, con estado separado por entorno y por dominio. No metas todo el estado en un solo archivo; usa un backend remoto y aplica Policy-as-Code con OPA o Sentinel para mantener la consistencia y el cumplimiento. Cuando las diferencias entre entornos sean de peso, usa directorios independientes por entorno.
A esta separación hay que sumarle runners aislados. Si mezclas runners de desarrollo y producción, abres una puerta innecesaria: una vulnerabilidad en un entorno menos seguro puede acabar afectando a producción. Por eso, separar superficies de riesgo aquí no es un lujo, sino una medida básica. Y el modelo on-premise sigue teniendo sentido cuando la soberanía del dato o el acceso interno son requisitos estrictos.
Rolling updates y rollback automático
Una vez que ya tienes entornos y secretos bien atados, toca mover versiones sin cortar el servicio. Aquí no hay una sola receta: el patrón de despliegue depende del riesgo, del coste y de lo rápido que necesites volver atrás.
En Kubernetes, el rolling update es el patrón de despliegue continuo más común. La idea es simple: sustituye los pods poco a poco mientras la aplicación sigue atendiendo tráfico. Si configuras maxUnavailable: 0, te aseguras de no perder capacidad durante el cambio, siempre que las readiness probes vayan validando los nuevos pods antes de ponerlos a trabajar.
Cuando necesitas un rollback inmediato, o no quieres exponer a toda la base de usuarios a un cambio de golpe, entran en juego blue-green y canary. Son dos enfoques muy usados cuando el margen de error es pequeño y no quieres jugártela.
El punto más delicado casi siempre está en las migraciones de base de datos. Ahí es donde muchos despliegues “parecían ir bien” hasta que dejaron de irlo. Por eso conviene versionar las migraciones y ejecutarlas como un paso aparte antes de desplegar la app.
El último tramo es el rollback automático. Tras cada despliegue, monitoriza durante cinco minutos y revierte de forma automática si pasa cualquiera de estas cosas:
la tasa de errores HTTP 5xx supera el 1 %
el percentil 95 de latencia rebasa el umbral del servicio
los health checks fallan de forma consecutiva
Con ese control, el pipeline puede frenar o dar marcha atrás antes de que el problema crezca.
Seguridad, observabilidad y cumplimiento por defecto
La seguridad y la auditoría deben entrar en el pipeline desde el primer cambio. A partir de ese punto, cada cambio tiene que pasar controles automáticos antes de pisar producción.
Ejecuta SAST en cada PR, SCA sobre las dependencias y firma las imágenes antes del despliegue. Esto no se deja para el final. Son gates de CI que frenan problemas antes de que lleguen a producción.
Con OPA o Kyverno, bloquea los hallazgos críticos y altos. Los medios y bajos pueden quedarse como aviso, sin meter revisiones manuales que ralenticen el flujo.
Y no se trata solo de parar cambios inseguros. El pipeline también debe dejar trazabilidad completa de lo que aprueba. La observabilidad tiene que estar dentro del pipeline, no solo en producción. Exige métricas, logs en JSON con correlation ID y trazas correladas antes de promover cambios. Si entra PII, debe enmascararse de forma automática antes de llegar al sistema de agregación.
Además, genera un SBOM por cada release, guarda una auditoría inmutable y usa tokens efímeros mediante OIDC. Así ya puedes comprobar, con datos, si el pipeline está mejorando de verdad.
Métricas de salud del pipeline que importan
Si los KPI anteriores marcan el rumbo, estas métricas te dicen algo más directo: si el pipeline está sano ahora mismo. Aquí entran las métricas DORA, cuatro indicadores que sirven para medir la salud operativa del ciclo de entrega.
Hablamos de Lead Time for Changes, Deployment Frequency, MTTR y Change Failure Rate. La tabla de abajo las resume. Cuando el Lead Time se dispara, lo normal es encontrar aprobaciones manuales o pruebas demasiado lentas. Y si el MTTR se cuenta en horas en vez de minutos, suele haber un problema claro: faltan automatismos en los rollbacks o la observabilidad no da la talla.
Los equipos con pipelines maduros llegan a desplegar hasta 208 veces más a menudo que los que siguen dependiendo de procesos manuales. Visto en la práctica, estos son los umbrales que conviene vigilar:
Métrica DORA | Señal de alerta | Objetivo (nivel élite) |
|---|---|---|
Lead Time | Tiempo alto en "Pendiente de aprobación" | < 1 hora |
Deployment Frequency | Estancada pese al crecimiento del equipo | Bajo demanda (múltiples veces al día) |
MTTR | Horas en lugar de minutos | < 1 hora |
Change Failure Rate | Sube al añadir nuevas funcionalidades | 0 % – 15 % |
La forma más útil de trabajar esto es simple: elige una sola métrica por sprint y ataca su mayor cuello de botella. No intentes arreglarlo todo de golpe, porque ahí es donde muchos equipos se lían.
Si sube el Change Failure Rate, toca poner la estabilidad por delante de las nuevas funcionalidades. Ahí entra el concepto de error budget: mientras quede margen, el equipo puede innovar; cuando se agota, se para y se corrige.
Conclusión
Con estas prácticas, la meta ya no es automatizar por automatizar, sino escalar sin perder el control. Un pipeline CI/CD que aguante el ritmo se monta por fases: velocidad con cabeza, entornos reproducibles, despliegues seguros y observación constante. La diferencia no está en meter más herramientas, sino en hacer bien lo básico y repetirlo sin fallar.
Si el equipo no puede mantener esta disciplina por sí solo, conviene contar con apoyo especializado para la implementación y el mantenimiento. Niom Solutions puede ayudar con el diseño, la automatización, las integraciones y el mantenimiento del pipeline.
Empieza con un servicio crítico, valida el flujo y llévalo después al resto.
FAQs
¿Por dónde empiezo con CI/CD?
Empieza con un pipeline mínimo y fácil de repetir, conectado a tu VCS: cada push o merge debe lanzar linters, tests unitarios y una build que genere el artefacto.
Después, añade fases separadas para staging con pruebas extra y, antes de pasar a producción, despliegues progresivos. Así bajas el riesgo: si algo falla, puedes apoyar el proceso con rollback automático y feature flags para activar cambios según un porcentaje del tráfico.
¿Cuándo elegir canary o blue-green?
Depende de lo que quieras conseguir con el despliegue y del nivel de riesgo que estés dispuesto a aceptar.
Blue-green funciona con dos entornos de producción idénticos. La idea es simple: mantienes la versión actual en un entorno y preparas la nueva en el otro. Cuando compruebas que todo va bien, desvías todo el tráfico a la nueva versión. Esto permite una transición limpia y, si algo falla, una reversión casi inmediata. Es el típico enfoque de “cambio de un golpe”, pero con red de seguridad.
Canary, en cambio, va paso a paso. Los cambios se liberan primero a una parte del tráfico o a un grupo concreto de usuarios. Así puedes ver qué pasa en producción de verdad antes de abrirlo al 100 %. Suele ser la mejor opción si necesitas vigilar el impacto real del cambio, la latencia o los errores antes del despliegue completo.
¿Qué métricas debo vigilar primero?
Prioriza las métricas que enseñan lo que vive el usuario de verdad. Empieza por la lógica RED en los endpoints críticos: tasa de peticiones, errores y latencia.
Súmale métricas de negocio, como pagos completados o tareas finalizadas. En la parte operativa, vigila la disponibilidad, el MTTR y la observabilidad por cliente o tenant para detectar anomalías antes de que vayan a más.