Estrategias para Startups: Controlar Deuda Técnica
DevOps
Identifica, prioriza y reduce la deuda técnica en startups: registra atajos, mide fricción y reserva 15–20% del sprint.

Si no controlas la deuda técnica desde el MVP, acabarás pagando más en tiempo, bugs y dinero. Yo lo resumiría así: anota cada atajo, mide la fricción, ordena por impacto, y reserva un 15–20 % de cada sprint para arreglar lo que ya te está frenando.
Hay un dato que pesa: alrededor del 30 % de los CIO dice que más del 20 % del presupuesto de nuevos proyectos se desvía a pagar deuda técnica vieja. En una startup, eso puede mover por completo el roadmap.
Si tuviera que quedarme con lo principal, sería esto:
No intento eliminar toda la deuda. Intento que no se dispare.
Distingo entre deuda intencionada y accidental. No es lo mismo un atajo con fecha que un problema que nadie vio.
Vigilo cuatro zonas: frontend, APIs, datos e integraciones.
Registro la deuda en el backlog, con etiqueta, severidad y esfuerzo.
Marco como urgente lo que sigue abierto más de 90 días.
Priorizo por negocio, riesgo y uso real del módulo.
Pido test de regresión antes del fix, y meto controles en CI/CD.
Alineo producto, diseño e ingeniería con la misma definición de “hecho”.
No perpetúo el MVP ni dejo atajos sin ticket de vuelta.
En otras palabras: la deuda técnica no es solo código sucio; es una decisión de producto con coste futuro. Yo la trataría como cualquier otra tarea que afecta a ventas, experiencia de usuario o estabilidad del sistema.
Deuda técnica: cómo verla, entenderla y ponerle precio - Emilio Carrión
De dónde viene la deuda técnica en el desarrollo web y de apps
En desarrollo web y de apps, la deuda técnica suele nacer de tres frentes muy claros: plazos, arquitectura y mantenimiento.
Deuda intencionada vs. deuda accidental
La deuda intencionada responde a una meta concreta. Por ejemplo, sacar una demo a tiempo o validar una idea sin invertir de más al principio.
La deuda accidental es otra historia. Suele aparecer cuando los requisitos están mal definidos, falta revisión o el equipo aún no domina bien cierta parte del sistema. El resultado es simple: más coste y más fricción, pero sin aportar nada útil al producto.
En el día a día, esta diferencia no se queda en la teoría. Se nota en partes muy concretas del producto.
Zonas de alto riesgo: frontend, APIs, modelos de datos e integraciones
La deuda se acumula justo donde el producto más se mueve: la interfaz, los contratos de API, el modelo de datos y las integraciones.
En el frontend, el fallo más común es duplicar lógica en vez de reutilizar componentes. Parece una salida fácil, pero luego cada cambio obliga a tocar varias piezas a la vez.
En las APIs, el riesgo aparece cuando los contratos no están bien definidos o cuando se dejan valores fijos dentro del código. Eso suele romper cosas cuando el sistema crece o cuando varios equipos dependen de la misma capa.
En el esquema de base de datos, un diseño pensado solo para el MVP puede pasar factura más tarde. De hecho, una estructura mal planteada puede acabar exigiendo consultas que obligan a unir siete o más tablas para operaciones básicas.
Y en las integraciones con terceros, el problema suele avanzar en silencio. Las dependencias envejecen, dejan de recibir parches de seguridad y terminan bloqueando nuevas funciones.
Cómo las decisiones iniciales de stack y arquitectura condicionan el mantenimiento futuro
Las decisiones de los primeros sprints pesan más de lo que parece. Elegir un framework solo porque el equipo ya lo conoce, sin mirar cómo aguantará el paso del tiempo, puede acabar en librerías incompatibles y fallos de seguridad acumulados.
Aquí es donde la arquitectura marca la diferencia. Una arquitectura modular permite añadir funciones sin tener que rehacer grandes partes del sistema.
Cuando estos focos se ven con claridad, resulta mucho más fácil medir la deuda y decidir qué atacar primero dentro del flujo de trabajo normal.
Cómo identificar, medir y priorizar la deuda técnica
Cómo Priorizar la Deuda Técnica en Startups: Estrategias y Señales Clave
Cuando la deuda ya se ha metido en módulos, APIs o datos, el reto es medirla sin romper el ritmo del equipo. Primero hay que hacerla visible. Luego toca decidir qué merece tiempo ahora y qué puede esperar un poco más.
Registra la deuda dentro de tu flujo de trabajo habitual
Apunta la deuda en Jira, Asana o en el gestor que uses cada día, con un tipo de tarea propio o una etiqueta como tech-debt, además de una severidad y una estimación de esfuerzo. Así, desarrollo y producto trabajan con la misma foto delante.
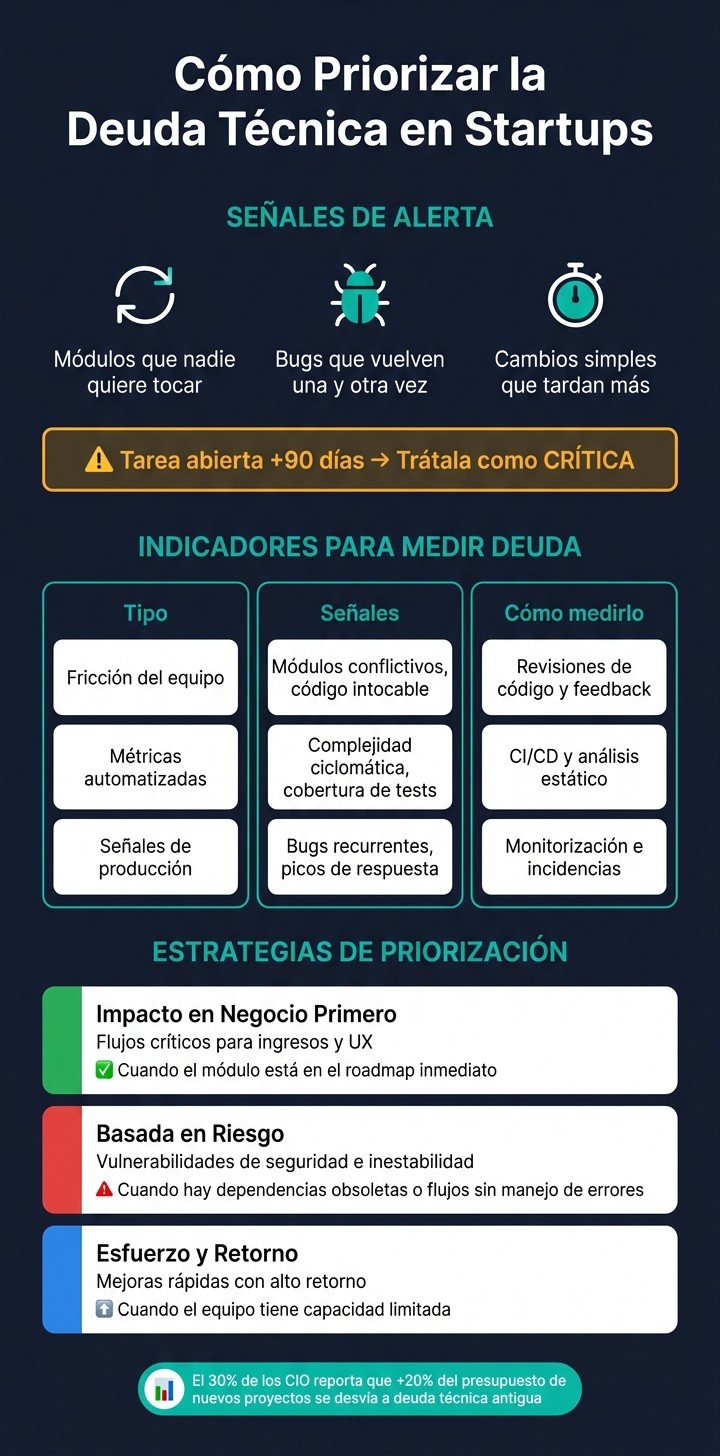
Dentro de ese registro, conviene fijarse en tres señales muy claras:
módulos que nadie quiere tocar
bugs que vuelven una y otra vez
cambios simples que cada vez tardan más
Si una tarea lleva abierta más de 90 días, trátala como prioritaria.
Ese registro te da una base. Los indicadores, en cambio, te enseñan por dónde empezar.
Usa indicadores simples para detectar deuda a tiempo
Tipo de indicador | Señales concretas | Cómo medirlo |
|---|---|---|
Fricción del equipo | Módulos que generan fricción, código que nadie quiere tocar | Revisiones de código y feedback del equipo |
Métricas automatizadas | Complejidad ciclomática, cobertura de pruebas, avisos de análisis estático | Herramientas de CI/CD y análisis estático |
Señales de producción | Bugs recurrentes, picos de tiempo de respuesta, patrones de incidencias | Monitorización y registros de incidencias |
Una señal especialmente útil es el tiempo que hace falta para implementar cambios simples. Si ese tiempo empieza a alargarse, la deuda está acumulando interés. Es como una tubería medio atascada: al principio apenas molesta, pero cada cambio acaba costando más de lo que debería.
Con estas señales, ya puedes decidir qué deuda conviene atacar antes.
Ordena la deuda por impacto en el negocio, riesgo y fase del roadmap
No toda la deuda pesa igual. Ordénala por impacto, riesgo y urgencia de producto.
Aquí ayuda pensar en principal e interés: si un módulo se toca todos los días, conviene pagarlo antes; si apenas se toca, puede esperar.
Estrategia | Foco | Cuándo aplicarla |
|---|---|---|
Impacto en negocio primero | Flujos críticos para ingresos y experiencia de usuario | Cuando el módulo afectado está en el plan de producto inmediato |
Basada en riesgo | Vulnerabilidades de seguridad e inestabilidad del sistema | Cuando hay dependencias obsoletas o flujos sin manejo de errores |
Basada en esfuerzo y retorno | Mejoras rápidas con alto retorno | Cuando el equipo tiene capacidad limitada y necesita victorias rápidas |
Dicho de forma simple: si algo frena ventas, rompe la experiencia de usuario o mete al sistema en una zona frágil, no conviene dejarlo para más adelante.
Con la deuda ya priorizada, el siguiente paso es reservar capacidad para corregirla.
Estrategias prácticas para frenar la acumulación de deuda
Con la deuda ya ordenada por impacto y riesgo, el siguiente paso es mucho más terrenal: convertir esa lista en hábitos de trabajo. Aquí funcionan tres palancas muy claras: reservar capacidad, trabajar con una arquitectura modular y acordar reglas de calidad compartidas. La idea es simple: que cada sprint no vuelva a fabricar la misma deuda de siempre.
Reserva capacidad para deuda técnica
La manera más directa de evitar que la deuda técnica se quede siempre para “luego” es reservar un porcentaje fijo de la capacidad de cada sprint para atenderla. Si no se aparta ese hueco desde el principio, casi siempre acaba perdiendo frente a lo urgente.
También ayuda aplicar la Boy Scout Rule: dejar el código un poco más limpio de como lo encontraste en cada tarea. No hace falta montar una gran refactorización cada vez. A veces basta con renombrar algo confuso, borrar código muerto o simplificar una parte enredada.
Y hay otro punto que marca la diferencia: registrar cada elemento de deuda con su ticket, severidad y estimación de esfuerzo. Si no está escrito y visible, se difumina. Y lo que se difumina, se repite.
Usa arquitectura, pruebas y CI/CD para cortar los problemas recurrentes
Cuando los mismos fallos vuelven una y otra vez, no suele ser mala suerte. Suele haber un problema de base. Por eso conviene dividir el sistema en módulos, versionar las APIs y limitar las dependencias entre componentes. Cuanto más acopladas estén las piezas, más fácil es que un cambio pequeño rompa media aplicación.
Con los bugs, una regla muy útil es esta: primero el test de regresión y después la corrección. Así te aseguras de que el fallo queda cubierto y no reaparece unas semanas más tarde por otra vía.
En el pipeline de CI/CD, merece la pena integrar controles automáticos que paren los problemas antes de que lleguen a producción. Por ejemplo:
linting automático
análisis estático
controles de seguridad
Ese filtro previo ayuda a detectar errores de forma temprana y reduce bastante el coste de arreglarlos.
Alinea producto, diseño e ingeniería en torno a reglas de calidad compartidas
Si la calidad depende de decisiones sueltas de cada persona, tarde o temprano aparecen grietas. Por eso conviene fijar reglas comunes entre producto, diseño e ingeniería. La deuda baja cuando todo el equipo trabaja con los mismos criterios, no cuando cada área interpreta “hecho” a su manera.
Un buen punto de partida es definir criterios de terminado compartidos que incluyan funcionalidad, pruebas y documentación. Parece básico, pero aquí es donde muchos equipos se tropiezan. Lo que no queda fijado como norma acaba reapareciendo en cada entrega, sprint tras sprint.
La deuda también debe vivir dentro del backlog, junto a las funcionalidades nuevas, no en una lista paralela que nadie mira. Si se separa, pierde visibilidad y acaba fuera de la conversación del equipo.
Y cuando se tome un atajo deliberado para cumplir un plazo, hay que dejarlo documentado en ese mismo momento: con un ticket de seguimiento y un plan concreto para devolver esa deuda. Si no se hace así, ese “ya lo arreglaremos” suele quedarse colgado más de la cuenta.
Conclusión: un plan para controlar la deuda técnica desde el primer día
Con la deuda ya localizada y priorizada, toca volver el control parte del día a día. Controlar la deuda técnica no es una tarea que se cierra y ya está. Es un hábito continuo. La idea es simple: pasar de detectar problemas a evitar que se acumulen con proceso y disciplina.
Acciones clave desde el MVP hasta la escala
Estas son las acciones que más impacto dejan desde el MVP hasta la escala:
No perpetúes el MVP.
Registra cada atajo en el backlog y enlázalo al código.
Reserva un 15–20 % del sprint para refactorización y mantenimiento.
Crea primero una prueba automatizada y luego corrige el bug.
Revisa la arquitectura antes de escalar y aplica el patrón Strangler Fig para sustituir componentes sin reescribir todo el sistema.
Si una deuda sigue abierta tras 90 días, trátala como crítica.
FAQs
¿Cuánta deuda técnica es aceptable en una startup?
No hay un nivel concreto de deuda técnica que sea “aceptable” en una startup.
Lo que importa de verdad es gestionarla de forma consciente y con criterio. Si se deja correr, acaba acumulándose y pasa factura: baja la calidad del software y los plazos empiezan a irse de las manos.
¿Qué tareas conviene arreglar primero?
Conviene poner el foco en las tareas que más pesan sobre la calidad y el mantenimiento del proyecto, sobre todo en el código que cambia a menudo. Si mejoras lo que el equipo toca cada día, evitas que la deuda técnica se dispare y que el trabajo se vuelva más lento de lo necesario.
Dicho de forma simple: si una parte del código se usa y se modifica sin parar, esa parte no puede quedarse “para más adelante” indefinidamente. Ahí es donde suelen aparecer los atascos, los fallos repetidos y la pérdida de tiempo.
También ayuda mucho registrar y hacer visible la deuda técnica para tratarla poco a poco. No hace falta resolverlo todo de golpe. Lo sensato es ir por partes y dar prioridad a lo que, si se deja aparcado, puede frenar el desarrollo y sumar riesgos con el paso del tiempo.
¿Cómo evitar que el MVP se convierta en un problema?
Para evitar que el MVP acabe pasando factura, conviene tratar la deuda técnica desde el principio. Eso implica dar prioridad a la calidad del código, incluir pruebas automatizadas y hacer revisiones frecuentes para detectar fallos cuanto antes.
También ayuda mucho mantener una comunicación clara entre desarrollo y producto. A partir de ahí, lo sensato es refactorizar poco a poco, sin esperar a que el problema crezca. Muchas empresas reservan entre el 20 % y el 25 % de cada sprint para rebajar esa deuda técnica y dejan constancia de las decisiones en un backlog específico.
Dicho de forma simple: si el equipo va arreglando lo que hoy funciona “a medias”, evita que mañana el MVP se vuelva más lento, más frágil y más caro de mantener.